


当人工智能(AI)工作负载扩展到单轨单集群有数千乃至数十万张GPU时,底层网络架构变得至关重要。无论是训练大语言模型、运行深度神经网络,还是构建GPUaaS(GPU-as-a-service)数据中心,网络都必须提供高带宽、无丢包的环境。否则工作负载优化将严重受限——GPU间微小的延时波动、拥塞或带宽问题,都可能破坏并行计算效率与整体性能。
传统上,基础设施团队构建AI集群主要采用两种架构:单轨优化架构与ToR优化架构。那么对于AI集群而言:
· 单轨架构与ToR架构孰优孰劣?
· 这二者是否是唯一选择?
· 新技术的突破是否正在重塑当前的AI集群架构格局?
扫码获取
《DriveNets FSE网络解决方案:大规模AI计算集群的高效网络后端部署方案》白皮书

架构解析:单轨与ToR的底层差异
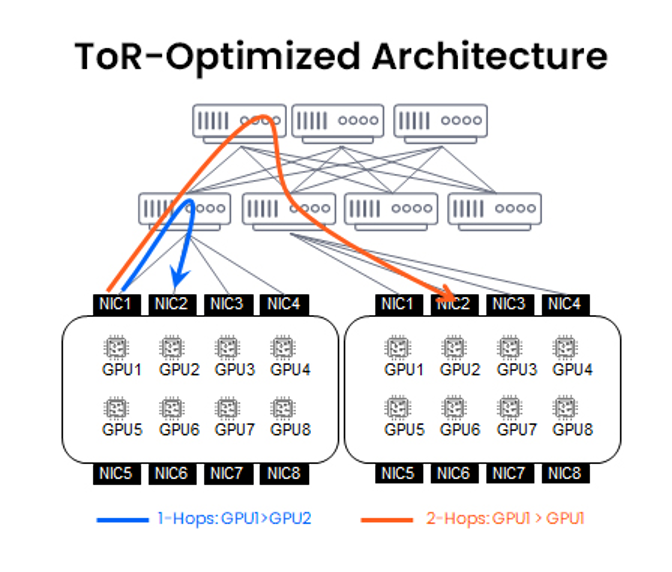
ToR优化架构
ToR架构设计在云服务及超大规模数据中心中较为常见。该架构下,每个机架配备一台ToR交换机,用于汇聚本机架内所有GPU流量;跨机架流量则由上游Spine交换机处理(基于Clos拓扑架构)。
优势
- 线缆管理更简易、总体成本更低,部署运维门槛较低;
- 符合网络团队认知标准(标准Leaf-Spine设计)。
局限
- 跨机架GPU通信需经历2次及以上交换机跳转;
- 存在过载风险与额外延时;
- 动态GPU间通信能力较弱,难以满足AI工作负载需求。
单轨优化架构
单轨架构通常通过专用交换层,将不同机架中的同序号GPU(如所有机架中的GPU0)横向连接。该设计最大程度减少延时与交换机跳转——这对集合操作或模型并行训练等工作负载至关重要。
优势
Benefits
- 同序号GPU间可实现超低延时的单跳通信;
- 专为高同步要求的AI训练工作负载设计。
局限
Limitations
- 跨轨流(如GPU1→GPU2)仍需要多跳路径进行通信;
- 部署复杂度高(线缆管理与额外交换层需求);
- 系统管理与扩展存在挑战。

鉴于这两种架构的固有局限,在面对复杂的大规模AI工作负载时,混合架构方案应运而生。
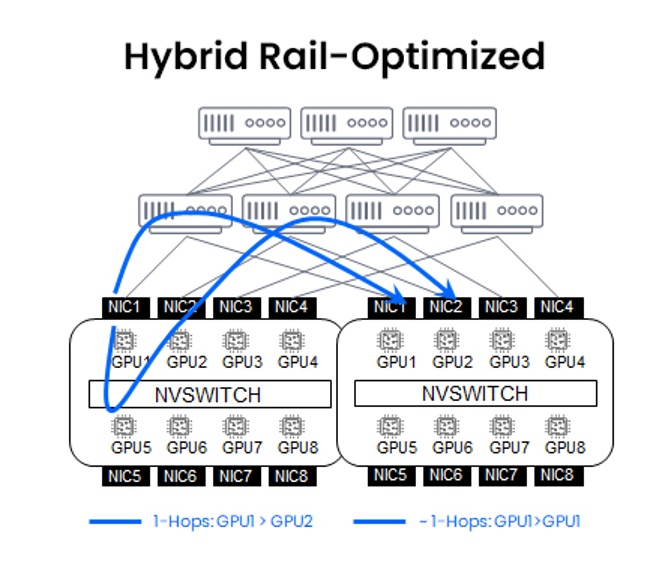
混合架构方案:单轨架构+NVLink/NVSwitch
该混合架构方案将跨机架同序号的GPU进行单轨互连,并与节点/DGX Pod内基于NVLink/NVSwitch的私有矩阵相结合,实现:
- 节点内GPU通信超高速化(通过NVLink/NVSwitch)
- 结构化、同编号的跨节点GPU同步延时显著压缩
但这种混合架构的解决方案仍然存在着不可避免的客观局限:
- 单轨架构在规模扩展时仍会失效,继而引发性能与运维层面的挑战
- NVLink/NVSwitch属私有技术,限制了系统灵活性及长期供应商选择空间
- 缺乏矩阵原生的、集群级别的调度机制,导致性能优化受限——在多租户环境中延时控制的瓶颈尤为突出
DriveNets Network Cloud-AI:突破ToR架构的性能天花板
DriveNets采用差异化路径——在保留ToR简洁性的同时,将其转型为全面向AI优化的矩阵。通过部署可调度、确定性延时的矩阵架构,以800G无丢包带宽连接所有ToR交换机,DriveNets NCAI网络解决方案基于ToR优化架构,在具备落地可行性的基础上,实现超大规模下的最优化。
FSE架构核心技术
DriveNets的FSE架构(基于可调度矩阵的以太网架构)融合三大创新:
- 信元喷射技术(Cell Spraying)
- 端到端虚拟输出队列(VOQs)
- 业务零感知故障切换(Zero-Impact Failover)
- 三者协同交付,共同构建出大规模AI集群的最优网络架构解决方案。
FSE网络架构方案打破了ToR的固有局限:不仅保留了任意GPU通信的模块化与灵活性,还规避了大规模单轨部署的复杂线缆管理与成本,并在此基础上实现了无丢包的高性能网络运行,完美支撑规模化AI工作负载。
核心优势总结
- 无丢包且确定性延时的通信保障
- 降低部署复杂性与成本
- 灵活弹性的任意GPU间通信
- 原生多租户支持,无需复杂调优

不可否认,传统ToR架构和单轨架构在基础网络架构层面有着相应的价值,但仍具备一定局限,使其难以适配大规模AI工作负载的实际需求。混合架构的网络解决方案在两者的基础上带来了一些改进,却也引入了新的复杂难题和对专业技术的依赖。
DriveNets NCAI网络解决方案针对大规模AI网络集群的部署,兼具了ToR架构模型的简洁性,与AI级性能的动态任意GPU互联能力,成为大规模高性能AI网络集群部署的理想底座。
其FSE方案(基于可调度矩阵的以太网架构)不仅彻底消除了ToR架构的传统局限,还具备了在规模化部署中所需的确定性延时和无丢包传输能力。
核心洞见
Key Takeaways
- 单轨架构
· 通过跨机架专用横向连接优化同序号GPU通信延时
· 具有部署复杂、扩展性差等问题 - ToR架构
· 在部署和运维方面更为简便
· 多跳通信路径阻碍延时敏感型AI工作负载性能 - 跨GPU通信共性难题
· 单轨架构中跨轨流量(如GPU1→GPU2)仍需多跳路径
· ToR架构中非本机架GPU通信存在跳转瓶颈 - DriveNets NCAI网络解决方案
· 新一代AI网络矩阵架构方案
· 融合ToR架构的简洁性与单轨架构的性能优势
· 保持可扩展性的同时,实现了适用于大型AI集群的低延迟互联
常见问题
FAQs
Q:AI集群中单轨架构与ToR架构的核心差异是什么?
A:单轨架构:通过专用交换层,将不同机架中的同序号GPU横向互联,实现低延时单跳通信,适用于高同步需求的AI训练负载。ToR架构:通过ToR交换机汇聚机架内所有GPU,跨机架通信由上层Spine交换机处理。部署和运维上更简易,但多跳路径会导致更高的延时,在部分AI工作负载场景下并不理想。
Q:单轨优化架构在AI工作负载中有何局限?
A:虽然优化了同序号的GPU通信延时,但也存在着部署复杂度高(额外线缆与交换层)、系统扩展困难等挑战。且跨轨流量(如GPU1→GPU2)仍需多跳路径,继而增加延时,影响性能。
Q:DriveNets NCAI网络解决方案相较传统网络架构方案有何不同?
A:DriveNets NCAI网络解决方案是一种创新的混合架构方案:在保留传统ToR架构的简易性同时,继承单轨架构的性能优势。将传统ToR架构方案转型为功能全面的AI优化网络矩阵,目标是为大规模AI工作负载提供低延时、高吞吐连接能力,同时规避单轨架构的部署管理复杂度。


